
R1-AQA
R1AQA是一个基于强化学习优化的音频问答模型,在音频问答领域表现出色。
列在类别中:
开源音频人工智能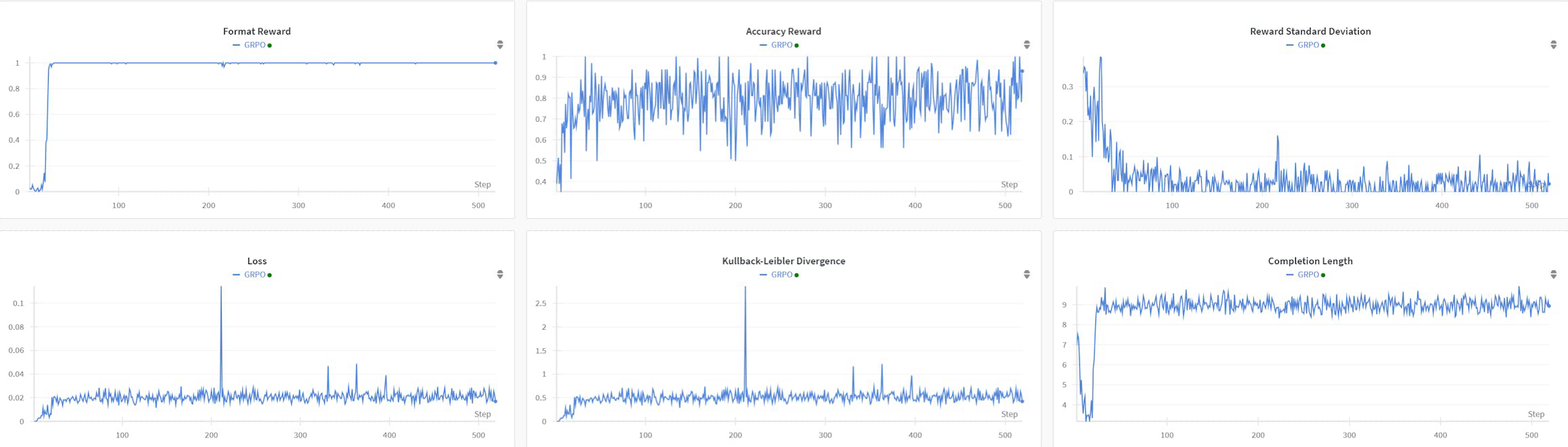
描述
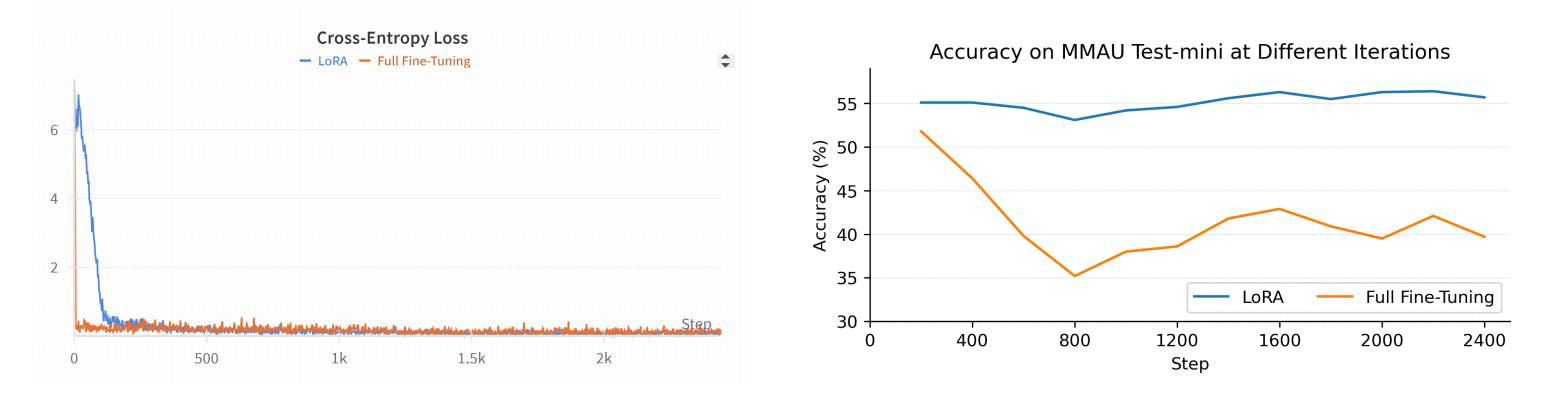
R1AQA是一个先进的音频问答(AQA)模型,基于Qwen2Audio7BInstruct,通过使用群体相对策略优化(GRPO)算法的强化学习(RL)进行优化。它在MMAU Testmini基准测试中仅使用38k后训练样本就达到了最先进的性能,展示了基于RL的方法在AQA任务中的有效性,而无需大型数据集。
如何使用 R1-AQA?
要使用R1AQA,请下载模型并按照提供的说明准备您的数据集。然后,您可以运行评估脚本以测试模型在音频问答任务上的性能。
核心功能 R1-AQA:
1️⃣
在音频问答任务中表现出色
2️⃣
使用强化学习技术进行优化
3️⃣
利用群体相对策略优化算法
4️⃣
仅需少量后训练样本
5️⃣
支持多种音频模式进行问答
为什么要使用 R1-AQA?
| # | 使用案例 | 状态 | |
|---|---|---|---|
| # 1 | 增强基于音频的搜索引擎 | ✅ | |
| # 2 | 改善音频内容的无障碍功能 | ✅ | |
| # 3 | 开发互动音频学习工具 | ✅ | |
开发者 R1-AQA?
R1AQA模型由包括李刚、刘继忠、海因里希·丁克尔、牛亚东、张俊博和栾健等研究人员团队开发,他们在音频问答和强化学习领域做出了重要贡献。