
R1-AQA
R1AQA là một mô hình hỏi đáp âm thanh được tối ưu hóa thông qua học tăng cường, đạt được hiệu suất hàng đầu.
Liệt kê trong các danh mục:
Mã nguồn mởÂm thanhTrí tuệ nhân tạo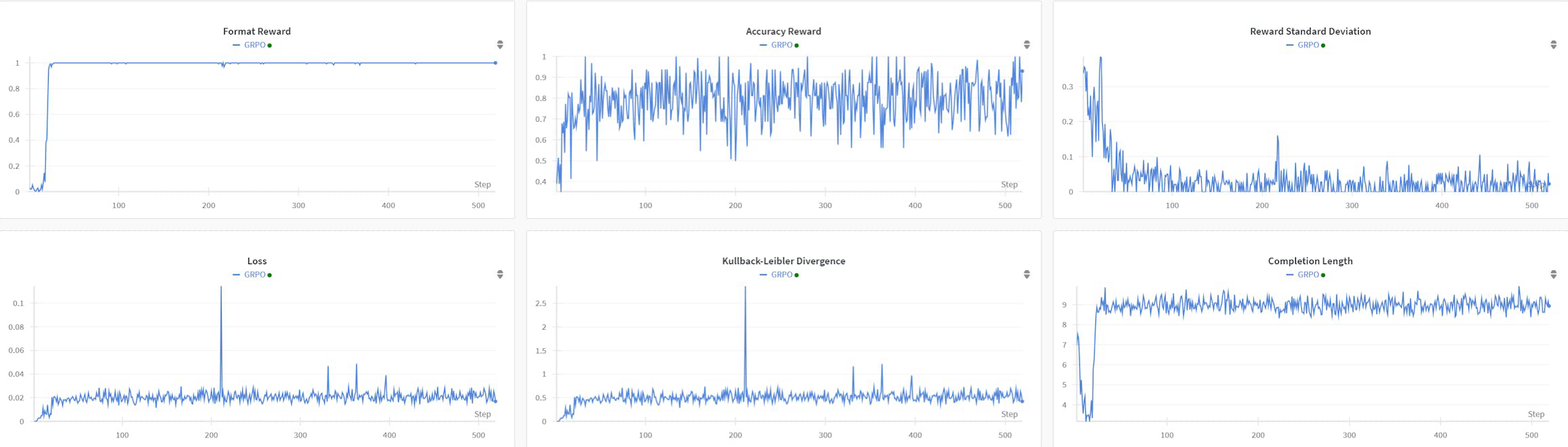
Mô tả
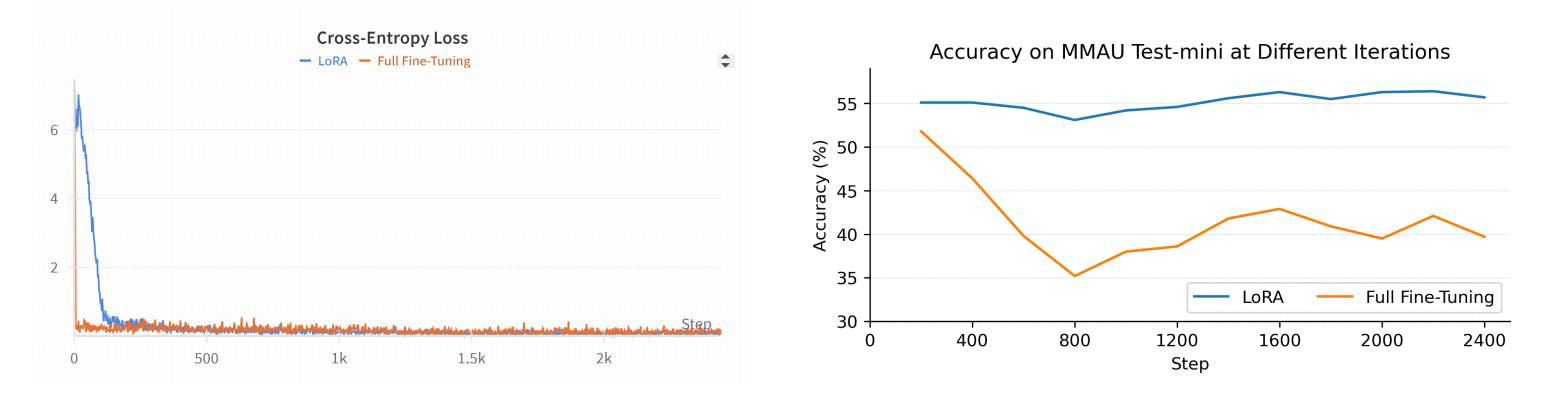
R1AQA là một mô hình trả lời câu hỏi âm thanh tiên tiến (AQA) dựa trên Qwen2Audio7BInstruct, được tối ưu hóa thông qua học tăng cường (RL) sử dụng thuật toán tối ưu hóa chính sách tương đối nhóm (GRPO). Nó đã đạt được hiệu suất hàng đầu trong các nhiệm vụ AQA trên chuẩn MMAU Testmini chỉ với 38k mẫu sau đào tạo, chứng minh hiệu quả của các phương pháp dựa trên RL trong các nhiệm vụ AQA mà không cần đến các tập dữ liệu lớn.
Cách sử dụng R1-AQA?
Để sử dụng R1AQA, tải mô hình về và làm theo hướng dẫn được cung cấp để chuẩn bị tập dữ liệu của bạn. Sau đó, bạn có thể chạy các kịch bản đánh giá để kiểm tra hiệu suất của mô hình trong các nhiệm vụ trả lời câu hỏi âm thanh.
Tính năng chính của R1-AQA:
1️⃣
Hiệu suất hàng đầu trong các nhiệm vụ trả lời câu hỏi âm thanh
2️⃣
Được tối ưu hóa bằng các kỹ thuật học tăng cường
3️⃣
Sử dụng thuật toán tối ưu hóa chính sách tương đối nhóm
4️⃣
Chỉ cần một số lượng nhỏ mẫu sau đào tạo
5️⃣
Hỗ trợ nhiều phương thức âm thanh khác nhau cho việc trả lời câu hỏi
Tại sao nên sử dụng R1-AQA?
| # | Trường hợp sử dụng | Trạng thái | |
|---|---|---|---|
| # 1 | Cải thiện các công cụ tìm kiếm dựa trên âm thanh | ✅ | |
| # 2 | Nâng cao các tính năng truy cập cho nội dung âm thanh | ✅ | |
| # 3 | Phát triển các công cụ học tập âm thanh tương tác | ✅ | |
Do ai phát triển R1-AQA?
Mô hình R1AQA được phát triển bởi một nhóm các nhà nghiên cứu bao gồm Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang và Jian Luan, những người đã có những đóng góp đáng kể cho lĩnh vực trả lời câu hỏi âm thanh và học tăng cường.