
R1-AQA
R1AQA é um modelo de perguntas e respostas de áudio otimizado por aprendizado por reforço, alcançando desempenho de ponta.
Listado em categorias:
Código abertoÁudioInteligência artificial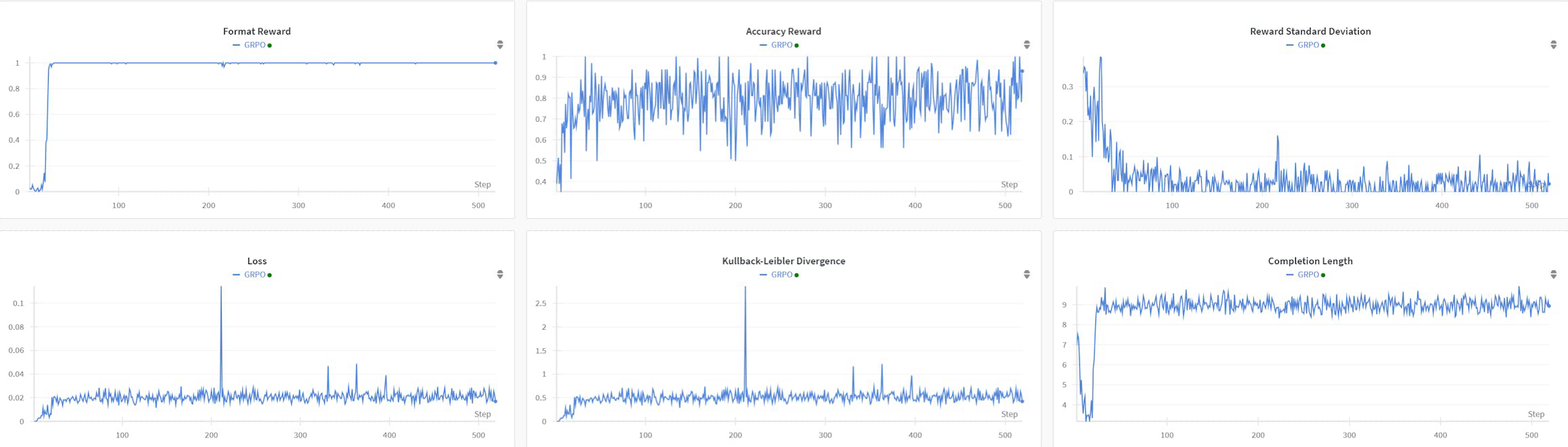
Descrição
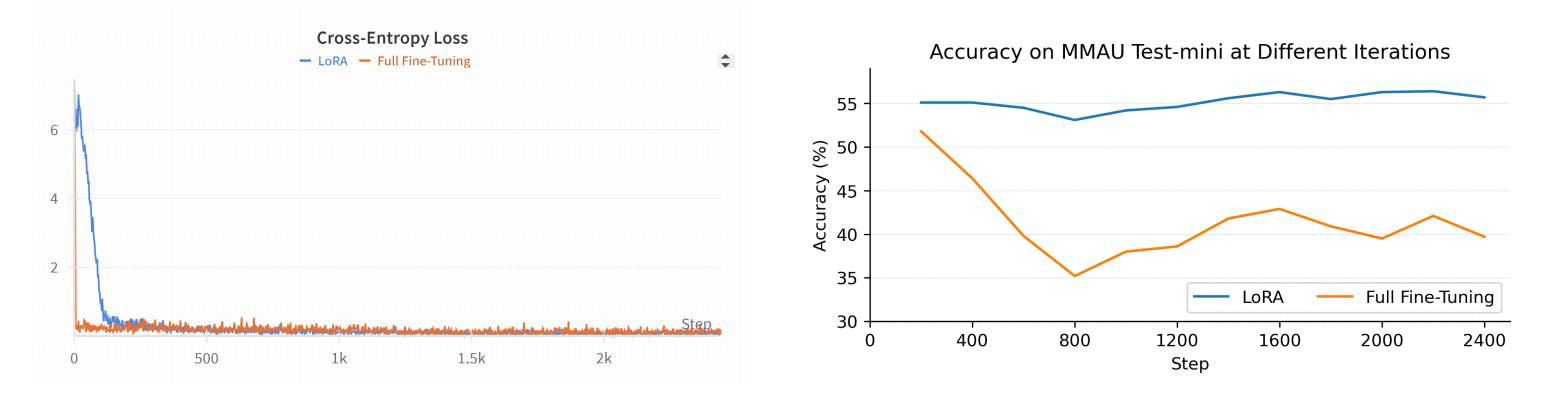
R1AQA é um modelo avançado de resposta a perguntas em áudio (AQA) baseado no Qwen2Audio7BInstruct, otimizado através de aprendizado por reforço (RL) usando o algoritmo de otimização de política relativa em grupo (GRPO). Ele alcançou desempenho de ponta no benchmark MMAU Testmini com apenas 38k amostras pós-treinamento, demonstrando a eficácia das abordagens baseadas em RL em tarefas de AQA sem a necessidade de grandes conjuntos de dados.
Como usar R1-AQA?
Para usar o R1AQA, baixe o modelo e siga as instruções fornecidas para preparar seu conjunto de dados. Você pode então executar os scripts de avaliação para testar o desempenho do modelo em tarefas de resposta a perguntas em áudio.
Recursos principais de R1-AQA:
1️⃣
Desempenho de ponta em tarefas de resposta a perguntas em áudio
2️⃣
Otimizado usando técnicas de aprendizado por reforço
3️⃣
Utiliza o algoritmo de otimização de política relativa em grupo
4️⃣
Requer apenas um pequeno número de amostras pós-treinamento
5️⃣
Suporta várias modalidades de áudio para resposta a perguntas
Por que usar R1-AQA?
| # | Caso de uso | Status | |
|---|---|---|---|
| # 1 | Aprimoramento de motores de busca baseados em áudio | ✅ | |
| # 2 | Melhoria de recursos de acessibilidade para conteúdo em áudio | ✅ | |
| # 3 | Desenvolvimento de ferramentas interativas de aprendizado em áudio | ✅ | |
Desenvolvido por R1-AQA?
O modelo R1AQA foi desenvolvido por uma equipe de pesquisadores, incluindo Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang e Jian Luan, que fizeram contribuições significativas para o campo de resposta a perguntas em áudio e aprendizado por reforço.