
DeepGEMM
DeepGEMM é uma biblioteca projetada para multiplicações de matrizes gerais FP8 (GEMMs) limpas e eficientes com escalonamento fino, escrita em CUDA.
Listado em categorias:
GitHubInteligência artificialCódigo aberto
Descrição
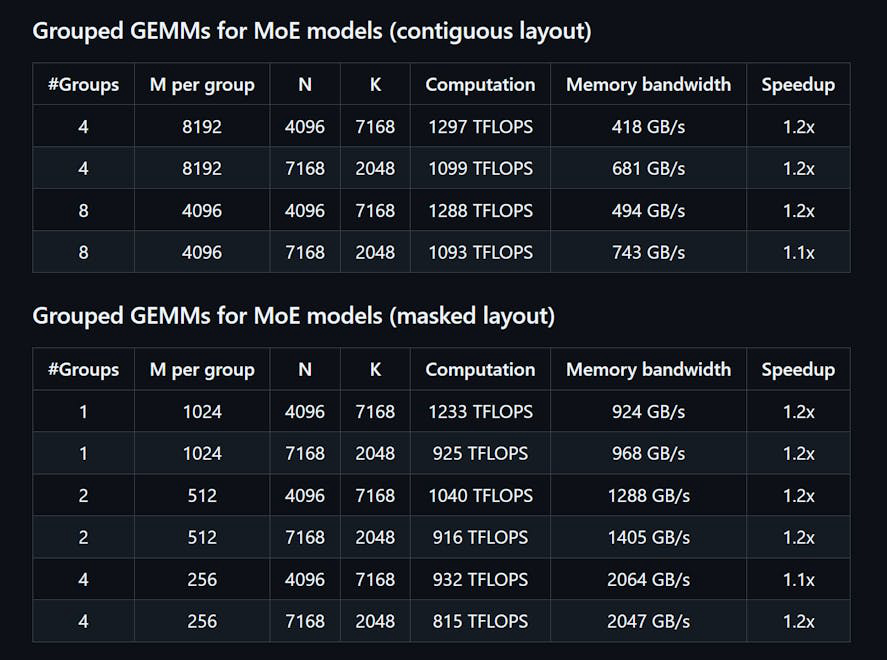
DeepGEMM é uma biblioteca projetada para multiplicações de matrizes gerais (GEMMs) em FP8 limpas e eficientes, com escalonamento de granularidade fina, conforme proposto no DeepSeekV3. Ela suporta tanto GEMMs agrupadas normais quanto Mix-of-Experts (MoE). Escrita em CUDA, a biblioteca compila todos os kernels em tempo de execução usando um módulo Just-In-Time (JIT) leve, não exigindo compilação durante a instalação. O DeepGEMM suporta exclusivamente núcleos tensor NVIDIA Hopper e emprega promoção de acumulação de dois níveis de núcleo CUDA para resolver a acumulação imprecisa de núcleos tensor FP8. Apesar de seu design leve, o desempenho do DeepGEMM iguala ou supera bibliotecas ajustadas por especialistas em várias formas de matriz.
Como usar DeepGEMM?
Para usar o DeepGEMM, instale a biblioteca via Python com 'python setup.py install'. Importe 'deepgemm' em seu projeto Python e chame as funções GEMM apropriadas para suas operações de matriz. Certifique-se de que seu ambiente atenda aos requisitos para as versões do CUDA e PyTorch.
Recursos principais de DeepGEMM:
1️⃣
Suporta GEMMs agrupadas normais e Mix-of-Experts (MoE)
2️⃣
Escrita em CUDA com compilação de kernel em tempo de execução
3️⃣
Otimizada para núcleos tensor NVIDIA Hopper
4️⃣
Utiliza promoção de acumulação de dois níveis para FP8
5️⃣
Design leve com uma única função de núcleo
Por que usar DeepGEMM?
| # | Caso de uso | Status | |
|---|---|---|---|
| # 1 | Multiplicação de matrizes eficiente para modelos de aprendizado profundo | ✅ | |
| # 2 | Otimização de desempenho em tarefas de inferência | ✅ | |
| # 3 | Utilização de precisão FP8 para cálculos eficientes em memória | ✅ | |
Desenvolvido por DeepGEMM?
DeepGEMM é desenvolvido por uma equipe que inclui Chenggang Zhao, Liang Zhao, Jiashi Li e Zhean Xu, que estão focados em fornecer soluções eficientes para multiplicação de matrizes em aplicações de aprendizado profundo.