
R1-AQA
R1AQAは、強化学習を通じて最適化された音声質問応答モデルであり、最先端のパフォーマンスを達成しています。
カテゴリーにリストされています:
オープンソースオーディオ人工知能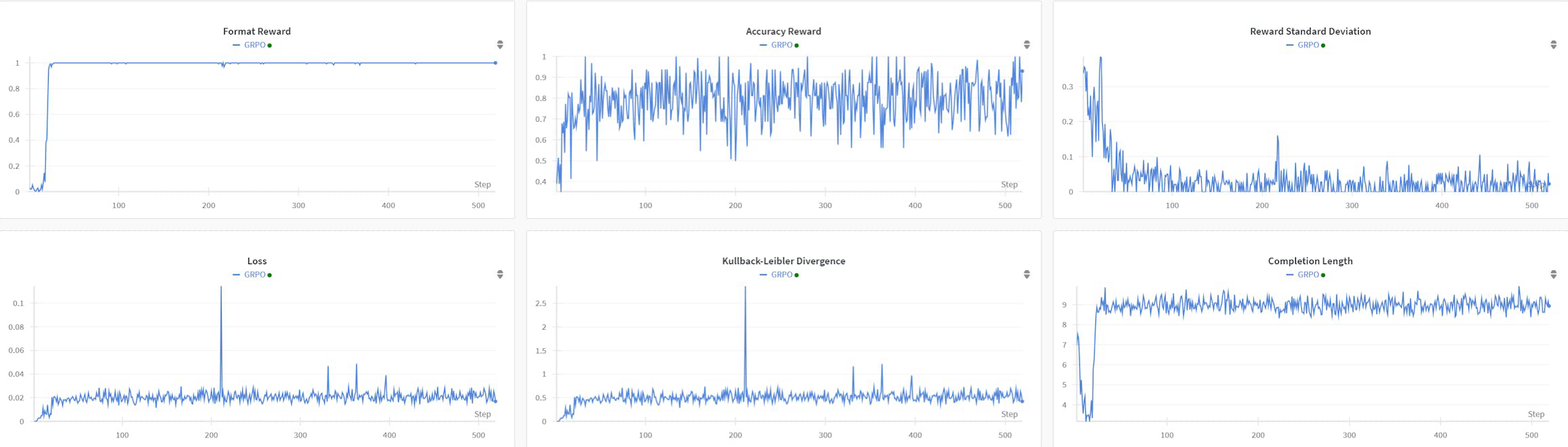
説明
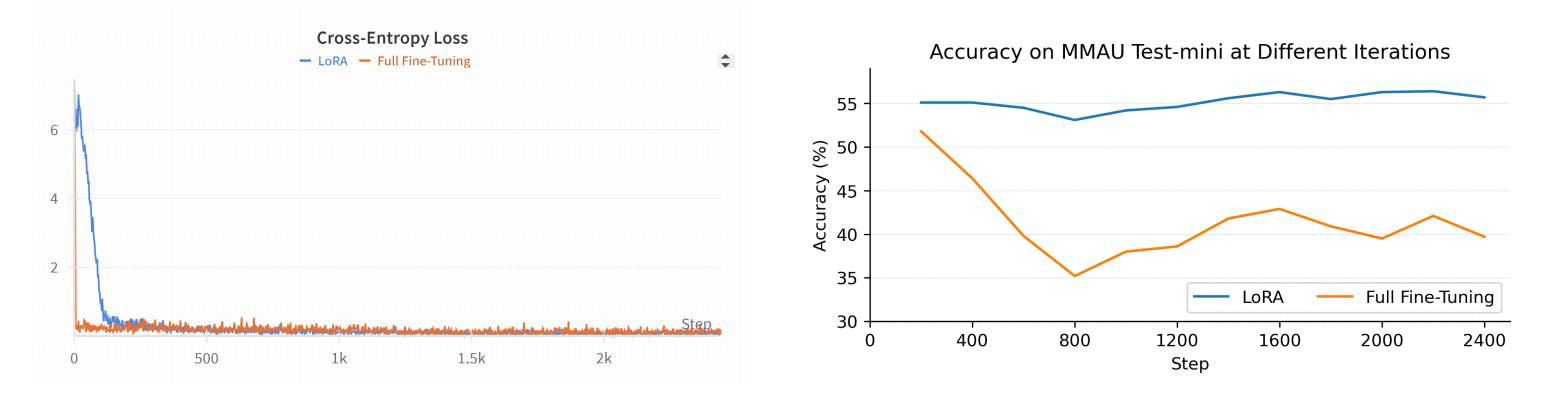
R1AQAは、Qwen2Audio7BInstructに基づいた高度な音声質問応答(AQA)モデルで、グループ相対ポリシー最適化(GRPO)アルゴリズムを使用した強化学習(RL)によって最適化されています。38kのポストトレーニングサンプルのみでMMAU Testminiベンチマークで最先端のパフォーマンスを達成しており、大規模なデータセットを必要とせずにAQAタスクにおけるRLベースのアプローチの効果を示しています。
使い方 R1-AQA?
R1AQAを使用するには、モデルをダウンロードし、データセットを準備するための指示に従ってください。その後、評価スクリプトを実行して音声質問応答タスクにおけるモデルのパフォーマンスをテストできます。
の主な機能 R1-AQA:
1️⃣
音声質問応答タスクにおける最先端のパフォーマンス
2️⃣
強化学習技術を使用して最適化
3️⃣
グループ相対ポリシー最適化アルゴリズムを利用
4️⃣
少数のポストトレーニングサンプルのみを必要
5️⃣
質問応答のためのさまざまな音声モダリティをサポート
なぜ使用するのか R1-AQA?
| # | ユースケース | ステータス | |
|---|---|---|---|
| # 1 | 音声ベースの検索エンジンの強化 | ✅ | |
| # 2 | 音声コンテンツのアクセシビリティ機能の改善 | ✅ | |
| # 3 | インタラクティブな音声学習ツールの開発 | ✅ | |
開発者 R1-AQA?
R1AQAモデルは、音声質問応答と強化学習の分野に重要な貢献をしているGang Li、Jizhong Liu、Heinrich Dinkel、Yadong Niu、Junbo Zhang、Jian Luanを含む研究者チームによって開発されました。