
R1-AQA
R1AQA è un modello di risposta a domande audio ottimizzato tramite apprendimento per rinforzo, raggiungendo prestazioni all'avanguardia.
Elencato nelle categorie:
Open SourceAudioIntelligenza artificiale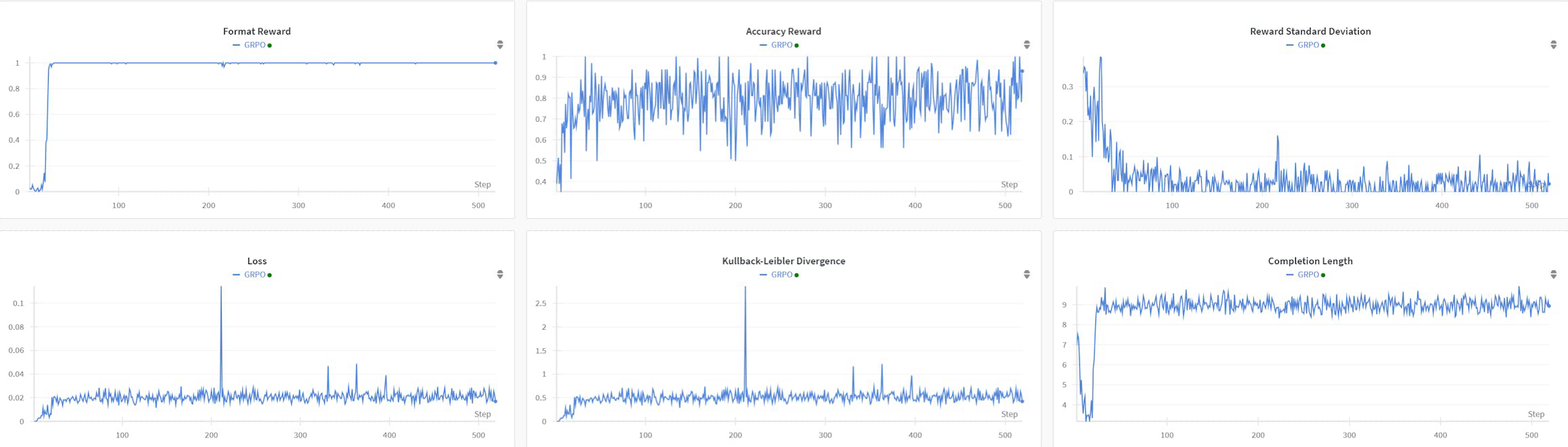
Descrizione
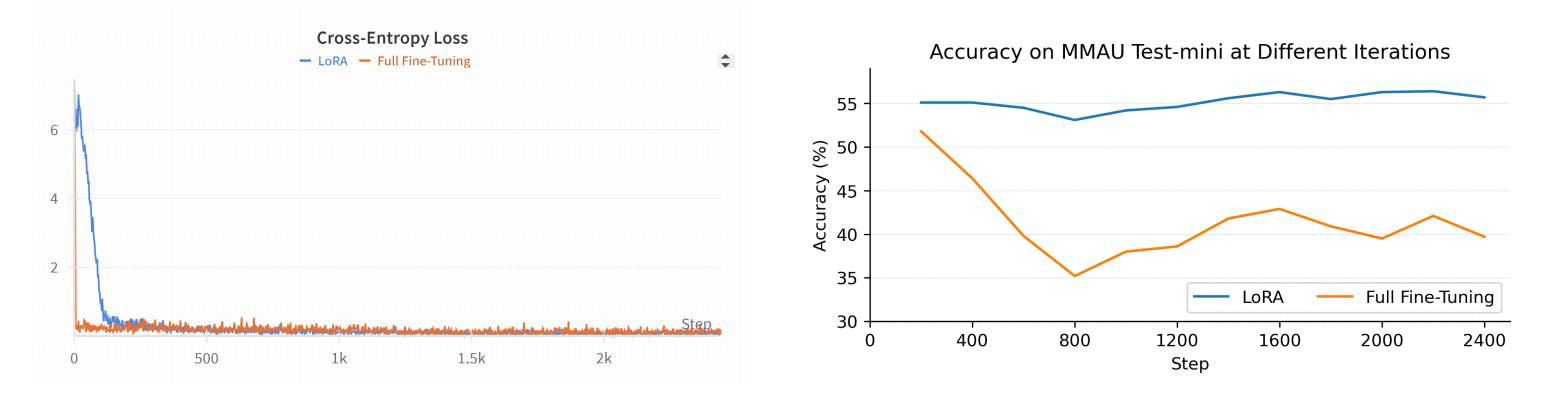
R1AQA è un modello avanzato di risposta a domande audio (AQA) basato su Qwen2Audio7BInstruct, ottimizzato attraverso l'apprendimento per rinforzo (RL) utilizzando l'algoritmo di ottimizzazione della politica relativa di gruppo (GRPO). Ha raggiunto prestazioni all'avanguardia sul benchmark MMAU Testmini con solo 38k campioni post-addestramento, dimostrando l'efficacia degli approcci basati su RL nei compiti di AQA senza la necessità di grandi dataset.
Come usare R1-AQA?
Per utilizzare R1AQA, scarica il modello e segui le istruzioni fornite per preparare il tuo dataset. Puoi quindi eseguire gli script di valutazione per testare le prestazioni del modello nei compiti di risposta a domande audio.
Funzionalità principali di R1-AQA:
1️⃣
Prestazioni all'avanguardia nei compiti di risposta a domande audio
2️⃣
Ottimizzato utilizzando tecniche di apprendimento per rinforzo
3️⃣
Utilizza l'algoritmo di ottimizzazione della politica relativa di gruppo
4️⃣
Richiede solo un numero ridotto di campioni post-addestramento
5️⃣
Supporta varie modalità audio per la risposta a domande
Perché potrebbe essere usato R1-AQA?
| # | Caso d'uso | Stato | |
|---|---|---|---|
| # 1 | Migliorare i motori di ricerca basati su audio | ✅ | |
| # 2 | Migliorare le funzionalità di accessibilità per i contenuti audio | ✅ | |
| # 3 | Sviluppare strumenti di apprendimento audio interattivi | ✅ | |
Sviluppato da R1-AQA?
Il modello R1AQA è sviluppato da un team di ricercatori tra cui Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang e Jian Luan, che hanno dato contributi significativi nel campo della risposta a domande audio e dell'apprendimento per rinforzo.