
DeepGEMM
DeepGEMM è una libreria progettata per moltiplicazioni di matrici generali FP8 (GEMMs) pulite ed efficienti con scalatura fine, scritta in CUDA.
Elencato nelle categorie:
GitHubIntelligenza artificialeOpen Source
Descrizione
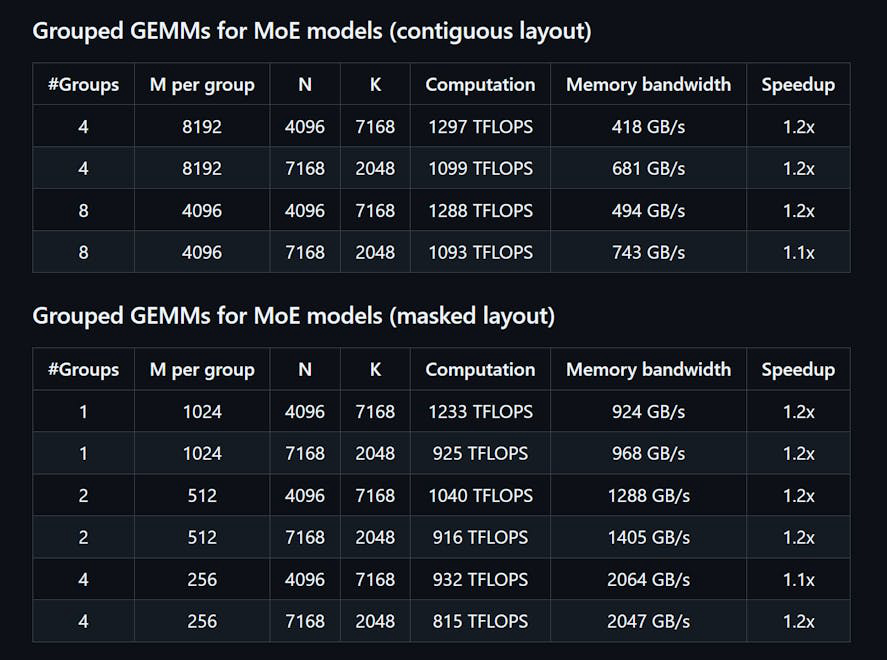
DeepGEMM è una libreria progettata per moltiplicazioni di matrici generali (GEMM) FP8 pulite ed efficienti con scalabilità fine, come proposto in DeepSeekV3. Supporta sia GEMM normali che GEMM raggruppati Mix-of-Experts (MoE). Scritta in CUDA, la libreria compila tutti i kernel durante il runtime utilizzando un modulo Just-In-Time (JIT) leggero, senza necessità di compilazione durante l'installazione. DeepGEMM supporta esclusivamente i core tensor NVIDIA Hopper e impiega la promozione di accumulo a due livelli dei core CUDA per affrontare l'accumulo impreciso dei core tensor FP8. Nonostante il suo design leggero, le prestazioni di DeepGEMM corrispondono o superano quelle delle librerie ottimizzate da esperti su varie forme di matrice.
Come usare DeepGEMM?
Per utilizzare DeepGEMM, installa la libreria tramite Python con 'python setup.py install'. Importa 'deepgemm' nel tuo progetto Python e chiama le funzioni GEMM appropriate per le tue operazioni su matrici. Assicurati che il tuo ambiente soddisfi i requisiti per le versioni di CUDA e PyTorch.
Funzionalità principali di DeepGEMM:
1️⃣
Supporta GEMM normali e GEMM raggruppati Mix-of-Experts (MoE)
2️⃣
Scritta in CUDA con compilazione dei kernel a runtime
3️⃣
Ottimizzata per i core tensor NVIDIA Hopper
4️⃣
Utilizza la promozione di accumulo a due livelli per FP8
5️⃣
Design leggero con una singola funzione kernel core
Perché potrebbe essere usato DeepGEMM?
| # | Caso d'uso | Stato | |
|---|---|---|---|
| # 1 | Moltiplicazione di matrici efficiente per modelli di deep learning | ✅ | |
| # 2 | Ottimizzazione delle prestazioni nei compiti di inferenza | ✅ | |
| # 3 | Utilizzo della precisione FP8 per calcoli efficienti in termini di memoria | ✅ | |
Sviluppato da DeepGEMM?
DeepGEMM è sviluppato da un team che include Chenggang Zhao, Liang Zhao, Jiashi Li e Zhean Xu, che si concentrano sulla fornitura di soluzioni efficienti per la moltiplicazione di matrici nelle applicazioni di deep learning.