
DeepGEMM
DeepGEMM adalah perpustakaan yang dirancang untuk perkalian matriks umum FP8 (GEMMs) yang bersih dan efisien dengan skala halus, ditulis dalam CUDA.
Terdaftar dalam kategori:
GitHubKecerdasan buatanSumber Terbuka
Deskripsi
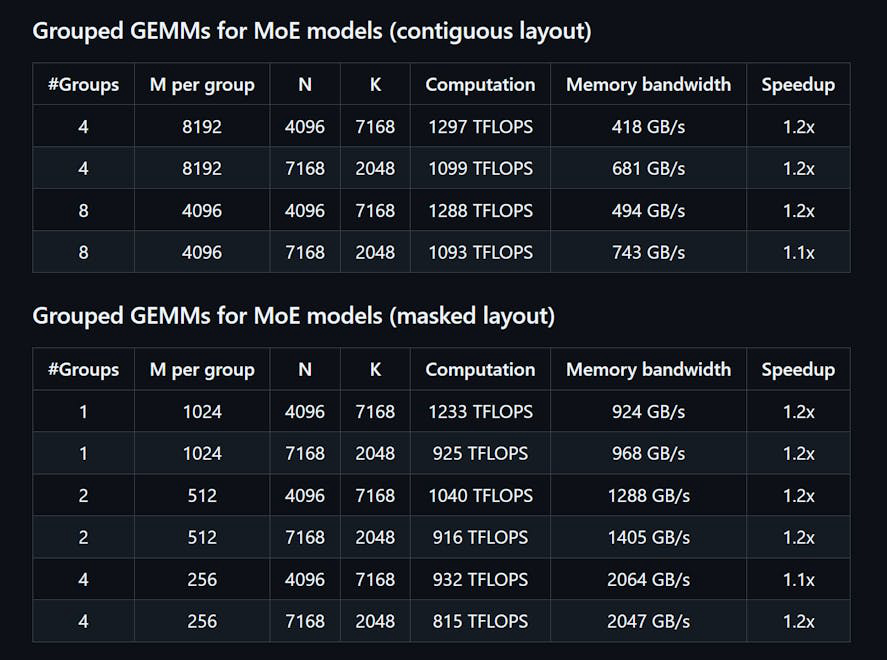
DeepGEMM adalah pustaka yang dirancang untuk Perkalian Matriks Umum (GEMM) FP8 yang bersih dan efisien dengan skala yang halus, seperti yang diusulkan dalam DeepSeekV3. Ini mendukung GEMM yang dikelompokkan normal dan Mix-of-Experts (MoE). Ditulis dalam CUDA, pustaka ini mengompilasi semua kernel saat runtime menggunakan modul Just-In-Time (JIT) yang ringan, tanpa memerlukan kompilasi selama instalasi. DeepGEMM secara eksklusif mendukung inti tensor NVIDIA Hopper dan menggunakan promosi akumulasi dua tingkat inti CUDA untuk mengatasi akumulasi inti tensor FP8 yang tidak tepat. Meskipun desainnya ringan, kinerja DeepGEMM sebanding atau melebihi pustaka yang disetel oleh ahli di berbagai bentuk matriks.
Cara menggunakan DeepGEMM?
Untuk menggunakan DeepGEMM, instal pustaka melalui Python dengan 'python setup.py install'. Impor 'deepgemm' dalam proyek Python Anda dan panggil fungsi GEMM yang sesuai untuk operasi matriks Anda. Pastikan lingkungan Anda memenuhi persyaratan untuk versi CUDA dan PyTorch.
Fitur inti dari DeepGEMM:
1️⃣
Mendukung GEMM yang dikelompokkan normal dan Mix-of-Experts (MoE)
2️⃣
Ditulis dalam CUDA dengan kompilasi kernel saat runtime
3️⃣
Dioptimalkan untuk inti tensor NVIDIA Hopper
4️⃣
Memanfaatkan promosi akumulasi dua tingkat untuk FP8
5️⃣
Desain ringan dengan satu fungsi kernel inti
Mengapa bisa digunakan DeepGEMM?
| # | Kasus Penggunaan | Status | |
|---|---|---|---|
| # 1 | Perkalian matriks yang efisien untuk model pembelajaran mendalam | ✅ | |
| # 2 | Mengoptimalkan kinerja dalam tugas inferensi | ✅ | |
| # 3 | Memanfaatkan presisi FP8 untuk komputasi yang efisien dalam memori | ✅ | |
Dikembangkan oleh DeepGEMM?
DeepGEMM dikembangkan oleh tim yang mencakup Chenggang Zhao, Liang Zhao, Jiashi Li, dan Zhean Xu, yang fokus pada penyediaan solusi efisien untuk perkalian matriks dalam aplikasi pembelajaran mendalam.