
R1-AQA
R1AQA est un modèle de question-réponse audio optimisé par apprentissage par renforcement, atteignant des performances de pointe dans le domaine.
Listé dans les catégories:
Open SourceAudioIntelligence artificielle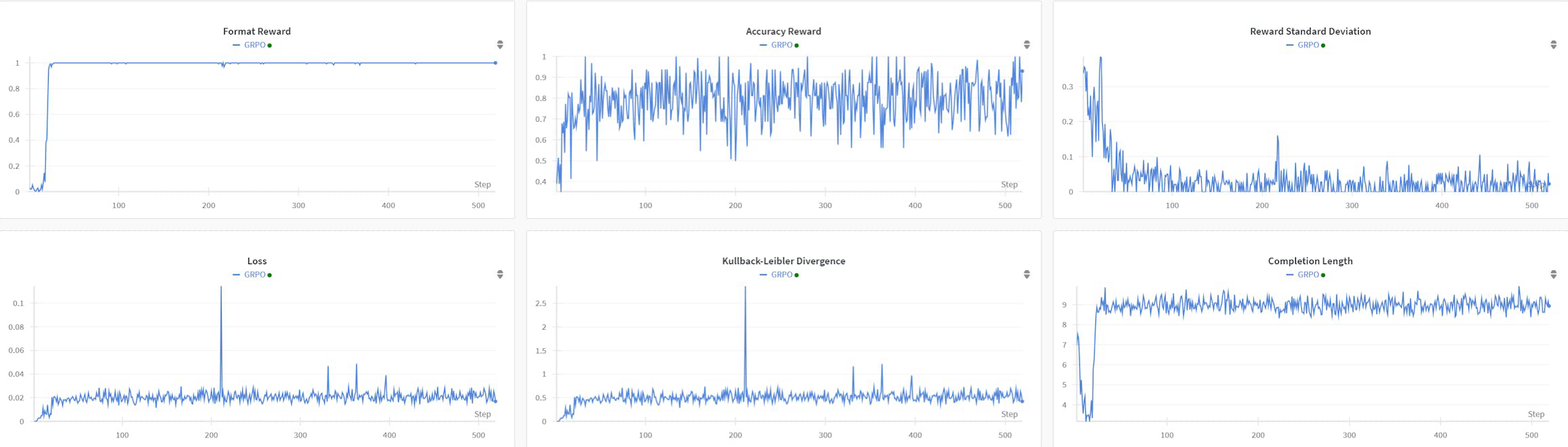
Description
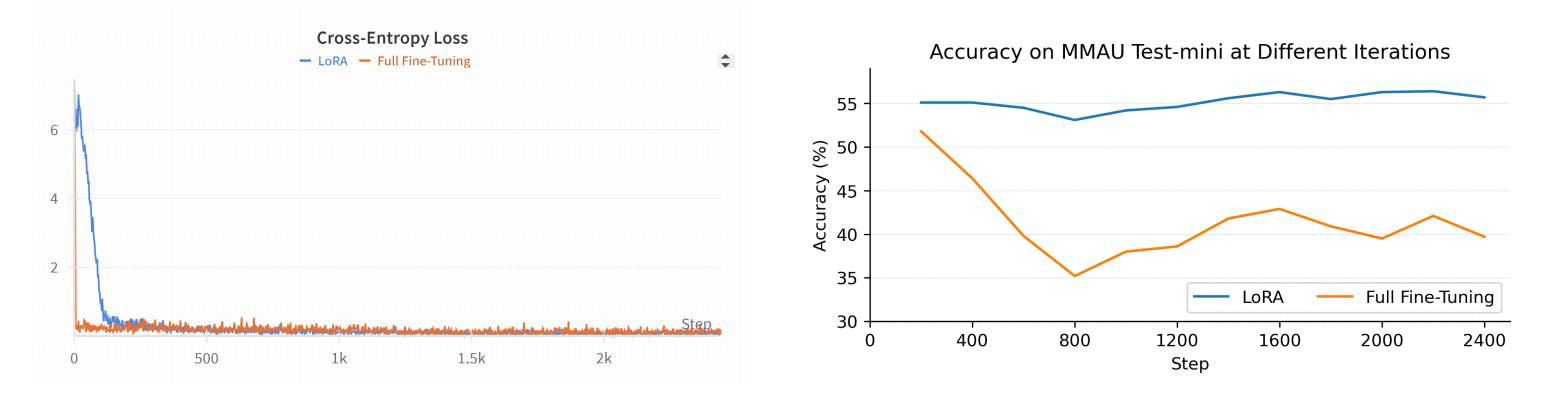
R1AQA est un modèle avancé de réponse à des questions audio (AQA) basé sur Qwen2Audio7BInstruct, optimisé par apprentissage par renforcement (RL) en utilisant l'algorithme d'optimisation de politique relative de groupe (GRPO). Il a atteint des performances de pointe sur le benchmark MMAU Testmini avec seulement 38k échantillons après entraînement, démontrant l'efficacité des approches basées sur le RL dans les tâches AQA sans avoir besoin de grands ensembles de données.
Comment utiliser R1-AQA?
Pour utiliser R1AQA, téléchargez le modèle et suivez les instructions fournies pour préparer votre ensemble de données. Vous pouvez ensuite exécuter les scripts d'évaluation pour tester les performances du modèle sur des tâches de réponse à des questions audio.
Fonctionnalités principales de R1-AQA:
1️⃣
Performances de pointe sur les tâches de réponse à des questions audio
2️⃣
Optimisé en utilisant des techniques d'apprentissage par renforcement
3️⃣
Utilise l'algorithme d'optimisation de politique relative de groupe
4️⃣
Nécessite seulement un petit nombre d'échantillons après entraînement
5️⃣
Prend en charge diverses modalités audio pour la réponse à des questions
Pourquoi pourrait-il être utilisé R1-AQA?
| # | Cas d'utilisation | Statut | |
|---|---|---|---|
| # 1 | Amélioration des moteurs de recherche basés sur l'audio | ✅ | |
| # 2 | Amélioration des fonctionnalités d'accessibilité pour le contenu audio | ✅ | |
| # 3 | Développement d'outils d'apprentissage audio interactifs | ✅ | |
Développé par R1-AQA?
Le modèle R1AQA est développé par une équipe de chercheurs comprenant Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang et Jian Luan, qui ont apporté des contributions significatives dans le domaine de la réponse à des questions audio et de l'apprentissage par renforcement.