
R1-AQA
R1AQA es un modelo de respuesta a preguntas de audio optimizado mediante aprendizaje por refuerzo, logrando un rendimiento de vanguardia.
Listado en categorías:
Código abiertoAudioInteligencia artificial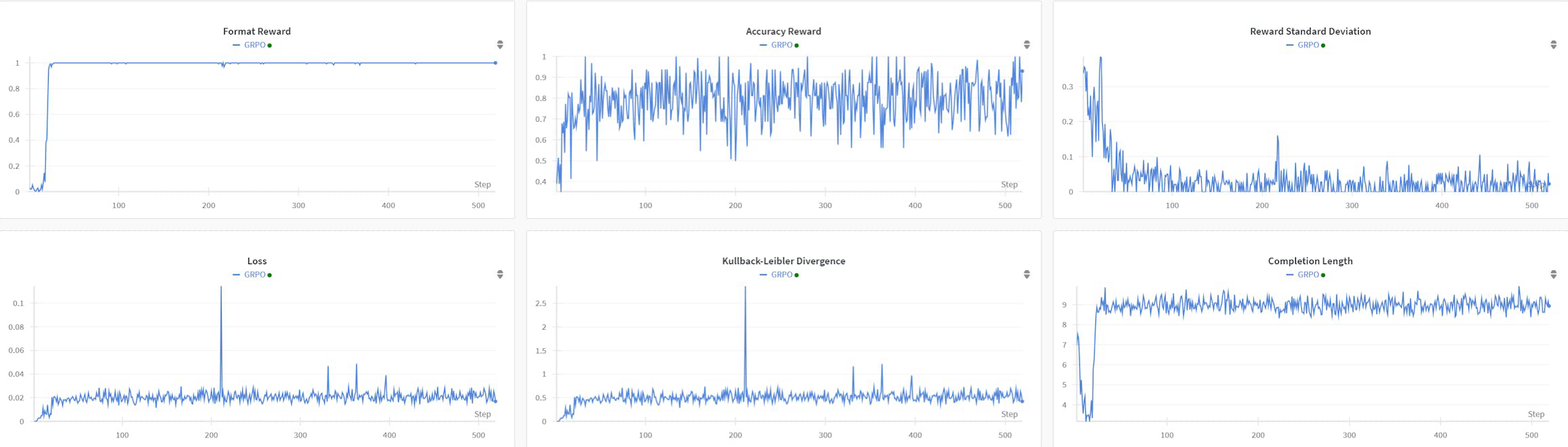
Descripción
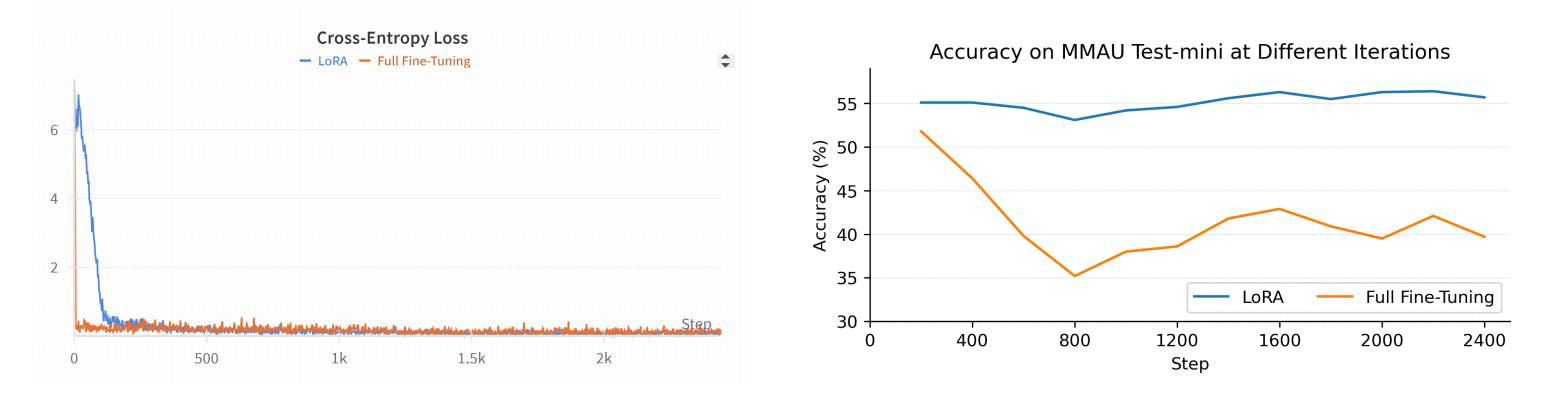
R1AQA es un modelo avanzado de respuesta a preguntas de audio (AQA) basado en Qwen2Audio7BInstruct, optimizado a través del aprendizaje por refuerzo (RL) utilizando el algoritmo de optimización de políticas relativas de grupo (GRPO). Ha logrado un rendimiento de vanguardia en el benchmark MMAU Testmini con solo 38k muestras post-entrenamiento, demostrando la efectividad de los enfoques basados en RL en tareas de AQA sin la necesidad de grandes conjuntos de datos.
Cómo usar R1-AQA?
Para usar R1AQA, descarga el modelo y sigue las instrucciones proporcionadas para preparar tu conjunto de datos. Luego puedes ejecutar los scripts de evaluación para probar el rendimiento del modelo en tareas de respuesta a preguntas de audio.
Características principales de R1-AQA:
1️⃣
Rendimiento de vanguardia en tareas de respuesta a preguntas de audio
2️⃣
Optimizado utilizando técnicas de aprendizaje por refuerzo
3️⃣
Utiliza el algoritmo de optimización de políticas relativas de grupo
4️⃣
Requiere solo un pequeño número de muestras post-entrenamiento
5️⃣
Soporta varias modalidades de audio para la respuesta a preguntas
Por qué podría ser usado R1-AQA?
| # | Caso de Uso | Estado | |
|---|---|---|---|
| # 1 | Mejorar motores de búsqueda basados en audio | ✅ | |
| # 2 | Mejorar las características de accesibilidad para contenido de audio | ✅ | |
| # 3 | Desarrollar herramientas de aprendizaje de audio interactivas | ✅ | |
Desarrollado por R1-AQA?
El modelo R1AQA es desarrollado por un equipo de investigadores que incluye a Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang y Jian Luan, quienes han hecho contribuciones significativas en el campo de la respuesta a preguntas de audio y el aprendizaje por refuerzo.