
DeepGEMM
DeepGEMM es una biblioteca diseñada para multiplicaciones de matrices generales FP8 (GEMMs) limpias y eficientes con escalado fino, escrita en CUDA.
Listado en categorías:
GitHubInteligencia artificialCódigo abierto
Descripción
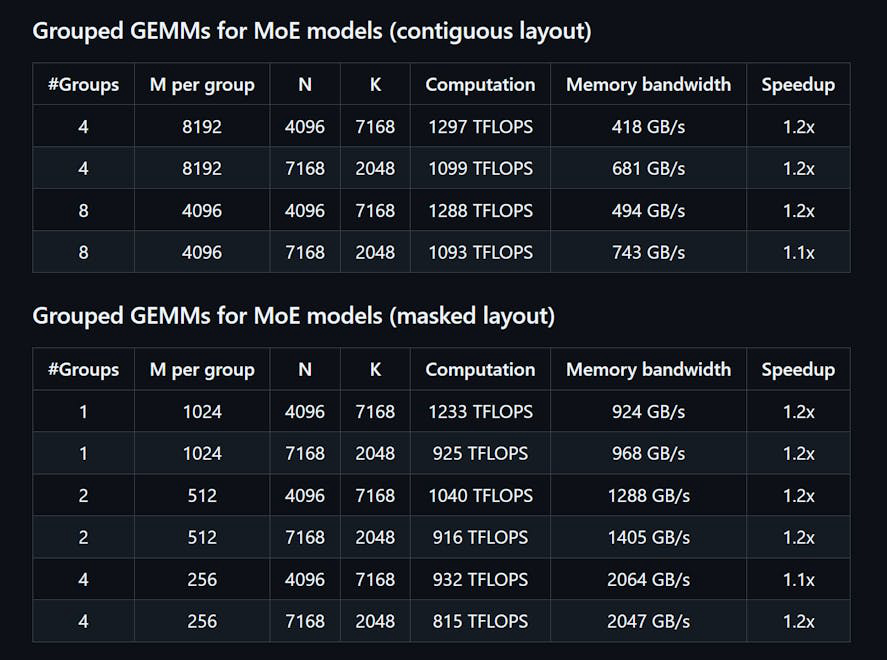
DeepGEMM es una biblioteca diseñada para multiplicaciones de matrices generales (GEMMs) FP8 limpias y eficientes con escalado de grano fino, como se propuso en DeepSeekV3. Soporta tanto GEMMs agrupados normales como de Mix-of-Experts (MoE). Escrito en CUDA, la biblioteca compila todos los kernels en tiempo de ejecución utilizando un módulo Just-In-Time (JIT) ligero, sin necesidad de compilación durante la instalación. DeepGEMM solo es compatible con los núcleos tensor NVIDIA Hopper y emplea la promoción de acumulación de dos niveles de núcleos CUDA para abordar la acumulación imprecisa de núcleos tensor FP8. A pesar de su diseño ligero, el rendimiento de DeepGEMM iguala o supera a las bibliotecas ajustadas por expertos en diversas formas de matrices.
Cómo usar DeepGEMM?
Para usar DeepGEMM, instala la biblioteca a través de Python con 'python setup.py install'. Importa 'deepgemm' en tu proyecto de Python y llama a las funciones GEMM apropiadas para tus operaciones de matriz. Asegúrate de que tu entorno cumpla con los requisitos para las versiones de CUDA y PyTorch.
Características principales de DeepGEMM:
1️⃣
Soporta GEMMs agrupados normales y de Mix-of-Experts (MoE)
2️⃣
Escrito en CUDA con compilación de kernel en tiempo de ejecución
3️⃣
Optimizado para núcleos tensor NVIDIA Hopper
4️⃣
Utiliza promoción de acumulación de dos niveles para FP8
5️⃣
Diseño ligero con una única función de kernel central
Por qué podría ser usado DeepGEMM?
| # | Caso de Uso | Estado | |
|---|---|---|---|
| # 1 | Multiplicación de matrices eficiente para modelos de aprendizaje profundo | ✅ | |
| # 2 | Optimización del rendimiento en tareas de inferencia | ✅ | |
| # 3 | Utilización de precisión FP8 para cálculos eficientes en memoria | ✅ | |
Desarrollado por DeepGEMM?
DeepGEMM es desarrollado por un equipo que incluye a Chenggang Zhao, Liang Zhao, Jiashi Li y Zhean Xu, quienes se enfocan en proporcionar soluciones eficientes para la multiplicación de matrices en aplicaciones de aprendizaje profundo.