
R1-AQA
R1AQA ist ein Audio-Fragenbeantwortungsmodell, das durch Verstärkungslernen optimiert wurde und eine herausragende Leistung bei Audiofragen zeigt.
Aufgeführt in Kategorien:
Open SourceAudioKünstliche Intelligenz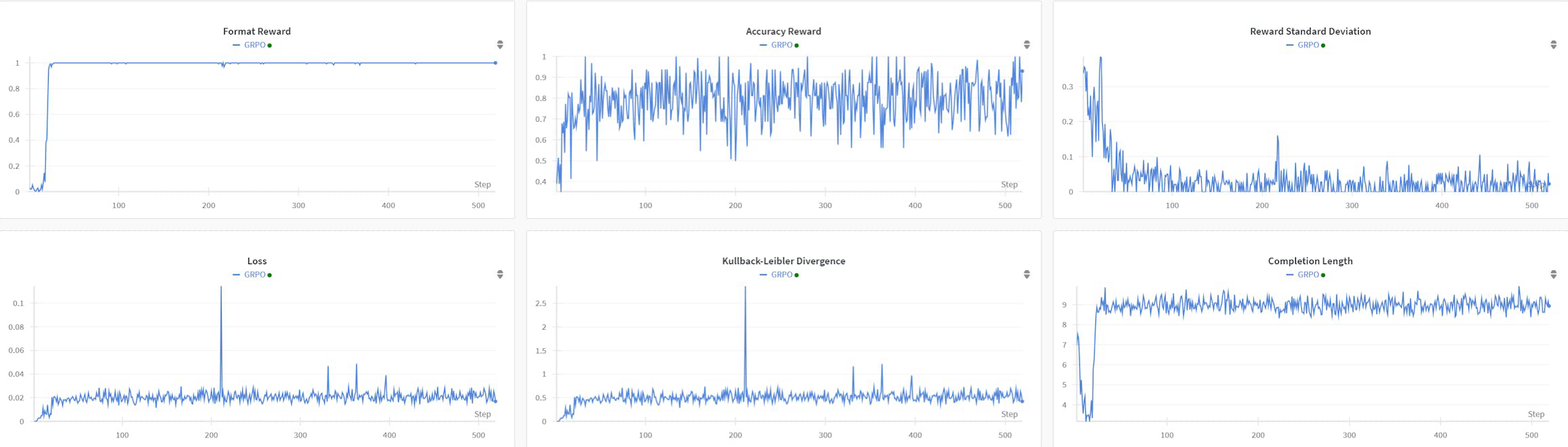
Beschreibung
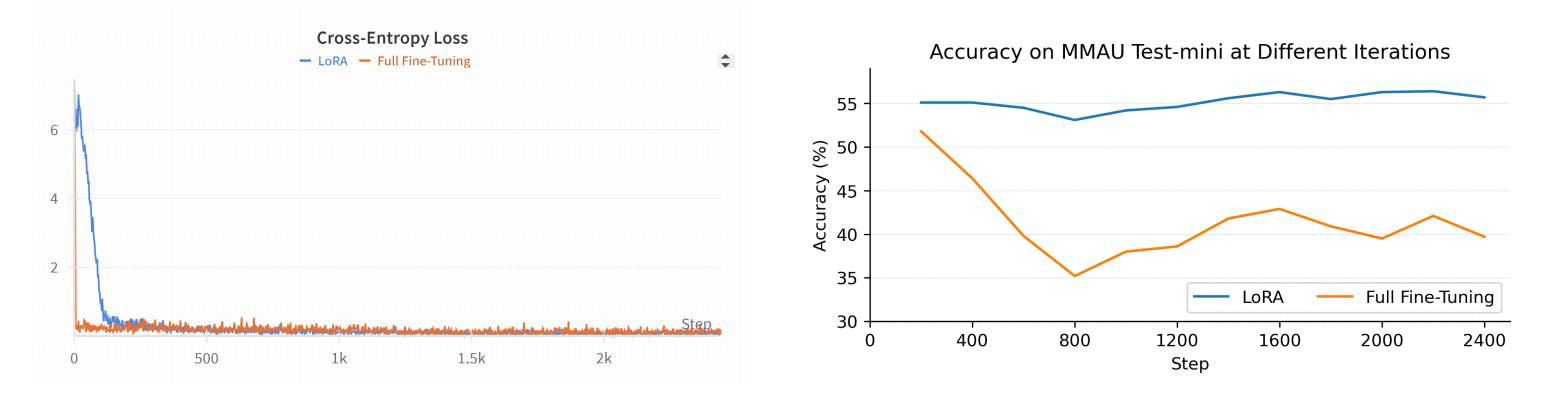
R1AQA ist ein fortschrittliches Audio-Fragenbeantwortungsmodell (AQA), das auf Qwen2Audio7BInstruct basiert und durch Verstärkungslernen (RL) mit dem Algorithmus der gruppenrelativen Politikoptimierung (GRPO) optimiert wurde. Es hat mit nur 38k Nachschulungsproben eine Spitzenleistung im MMAU Testmini-Benchmark erreicht und zeigt die Effektivität von RL-basierten Ansätzen in AQA-Aufgaben, ohne dass große Datensätze erforderlich sind.
Wie man benutzt R1-AQA?
Um R1AQA zu verwenden, laden Sie das Modell herunter und folgen Sie den bereitgestellten Anweisungen zur Vorbereitung Ihres Datensatzes. Sie können dann die Evaluierungsskripte ausführen, um die Leistung des Modells bei Audio-Fragenbeantwortungsaufgaben zu testen.
Hauptmerkmale von R1-AQA:
1️⃣
Spitzenleistung bei Audio-Fragenbeantwortungsaufgaben
2️⃣
Optimiert mit Techniken des Verstärkungslernens
3️⃣
Nutzen Sie den Algorithmus der gruppenrelativen Politikoptimierung
4️⃣
Benötigt nur eine kleine Anzahl von Nachschulungsproben
5️⃣
Unterstützt verschiedene Audio-Modi für die Fragenbeantwortung
Warum könnte verwendet werden R1-AQA?
| # | Anwendungsfall | Status | |
|---|---|---|---|
| # 1 | Verbesserung von audio-basierten Suchmaschinen | ✅ | |
| # 2 | Verbesserung der Barrierefreiheitsfunktionen für Audioinhalte | ✅ | |
| # 3 | Entwicklung interaktiver Audio-Lernwerkzeuge | ✅ | |
Wer hat entwickelt R1-AQA?
Das R1AQA-Modell wurde von einem Team von Forschern entwickelt, darunter Gang Li, Jizhong Liu, Heinrich Dinkel, Yadong Niu, Junbo Zhang und Jian Luan, die bedeutende Beiträge im Bereich der Audio-Fragenbeantwortung und des Verstärkungslernens geleistet haben.