
DeepGEMM
DeepGEMM ist eine Bibliothek für saubere und effiziente FP8 General Matrix Multiplications (GEMMs) mit feinkörniger Skalierung, die in CUDA geschrieben ist.
Aufgeführt in Kategorien:
GitHubKünstliche IntelligenzOpen Source
Beschreibung
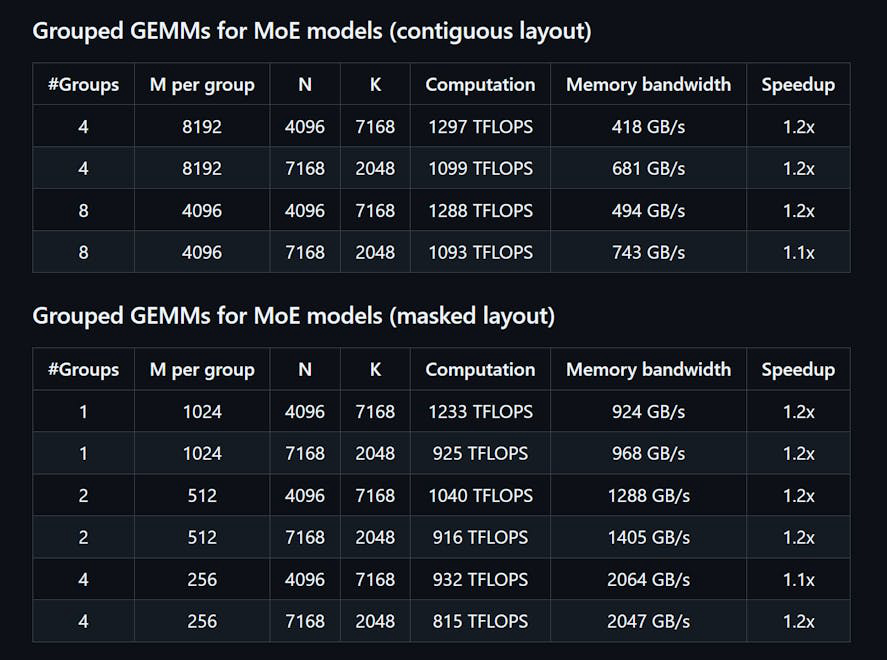
DeepGEMM ist eine Bibliothek, die für saubere und effiziente FP8 Allgemeine Matrixmultiplikationen (GEMMs) mit feinkörniger Skalierung entwickelt wurde, wie in DeepSeekV3 vorgeschlagen. Sie unterstützt sowohl normale als auch Mix-of-Experts (MoE) gruppierte GEMMs. Die Bibliothek ist in CUDA geschrieben und kompiliert alle Kerne zur Laufzeit mithilfe eines leichten Just-In-Time (JIT) Moduls, das keine Kompilierung während der Installation erfordert. DeepGEMM unterstützt ausschließlich NVIDIA Hopper Tensor-Kerne und verwendet die zweistufige Akkumulationsförderung von CUDA, um ungenaue FP8 Tensor-Kern-Akkumulationen zu adressieren. Trotz ihres leichten Designs entspricht die Leistung von DeepGEMM oder übertrifft die von Experten optimierten Bibliotheken bei verschiedenen Matrixformen.
Wie man benutzt DeepGEMM?
Um DeepGEMM zu verwenden, installieren Sie die Bibliothek über Python mit 'python setup.py install'. Importieren Sie 'deepgemm' in Ihr Python-Projekt und rufen Sie die entsprechenden GEMM-Funktionen für Ihre Matrixoperationen auf. Stellen Sie sicher, dass Ihre Umgebung die Anforderungen für CUDA- und PyTorch-Versionen erfüllt.
Hauptmerkmale von DeepGEMM:
1️⃣
Unterstützt normale und Mix-of-Experts (MoE) gruppierte GEMMs
2️⃣
In CUDA mit Laufzeitkernkompilierung geschrieben
3️⃣
Optimiert für NVIDIA Hopper Tensor-Kerne
4️⃣
Nutzen von zweistufiger Akkumulationsförderung für FP8
5️⃣
Leichtes Design mit einer einzigen Kernfunktionsimplementierung
Warum könnte verwendet werden DeepGEMM?
| # | Anwendungsfall | Status | |
|---|---|---|---|
| # 1 | Effiziente Matrixmultiplikation für Deep-Learning-Modelle | ✅ | |
| # 2 | Optimierung der Leistung bei Inferenzaufgaben | ✅ | |
| # 3 | Nutzung der FP8-Präzision für speichereffiziente Berechnungen | ✅ | |
Wer hat entwickelt DeepGEMM?
DeepGEMM wurde von einem Team entwickelt, zu dem Chenggang Zhao, Liang Zhao, Jiashi Li und Zhean Xu gehören, die sich darauf konzentrieren, effiziente Lösungen für die Matrixmultiplikation in Deep-Learning-Anwendungen bereitzustellen.